Introduction to NLP
NLP is a subfield of AI that analyzes text, speech, and other forms of human-generated language data. NLP makes it possible for computers to extract keywords and phrases, understand the intent of language, translate that to another language, or generate a response.
NLP can be used to create search engine algorithms, chatbots, speech recognition applications, and user sentiment recognition applications.
Why Python in NLP?
Python is typically used to work with text data because:
- Python is easy to learn.
- It allows for easier development of quick NLP application prototypes.
- Python is one of the most popular languages. It has huge community support, and installing new libraries with pip is effortless.
- A significant number of open-source NLP libraries are available in Python. Many machine learning libraries such as PyTorch, TensorFlow and Apache Spark also provide Python APIs.
- String and file operations with Python are effortless and straightforward.
A high-level overview of spaCy
spaCy is an open-source Python library for modern NLP. spaCy is shipped with pre-trained language models with word vectors for 60+ languages and it focuses on production and shipping code. spaCy is designed specifically for production use and helps you build applications that process and “understand” large volumes of text. It can be used to build information extraction or natural language understanding systems or to pre-process text for deep learning.
Installing spaCy
You can install spaCy with the following command using pip:
$ pip install spacyYou can import spaCy to your code editor using the following code:
import spacyInstalling language models
spaCy’s trained pipelines can be installed as Python packages. This means that they’re a component of your application, just like any other module. They’re versioned and can be defined as a dependency in your requirements.txt. Trained pipelines can be installed from a download URL or a local directory, manually or via pip. Their data can be located anywhere on your file system.
$ python -m spacy download en_core_web_mdTo download the exact package version
$ python -m spacy download en_core_web_sm-3.0.0 --directTo load the mode use the following code:
import spacy
nlp = spacy.load('en_core_web_md')
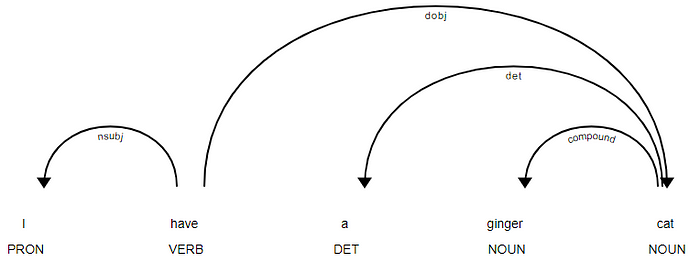
doc = nlp('I have a ginger cat.')Getting started with displaCy
Visualizing a dependency parse or named entities in a text is not only a fun NLP demo — it can also be incredibly helpful in speeding up development and debugging your code and training process.
https://explosion.ai/demos/displacy to use the interactive demo. The visualizer performs two syntactic parses, POS tagging and a dependency parse on the submitted text to visualize the sentence’s syntactic structure.
displaCy on Jupyter notebooks
from spacy import displacy
displacy.render(doc, style='dep')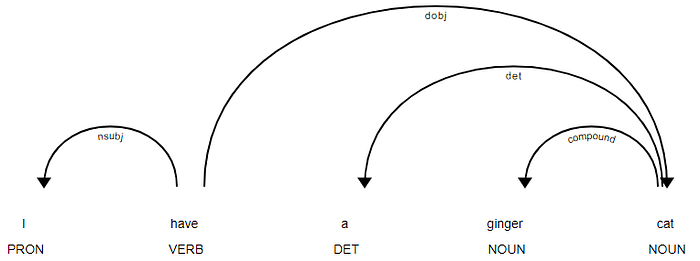
Entity visualizer
displaCy’s entity visualizer highlights the named entities in your text. Visit https://explosion.ai/demos/displacy-ent for the online demo.
Use the following code to identify the entities in your text on a Jupyter notebook.
doc2 = nlp('Bill Gates is the CEO of Microsoft')
displacy.render(doc2, style='ent')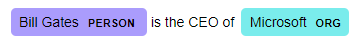
Github
You can find the Jupyter notebook for this article in the following link: https://github.com/jabirjamal/jabirjamal.com/tree/main/NLP/NLP-01
Reference