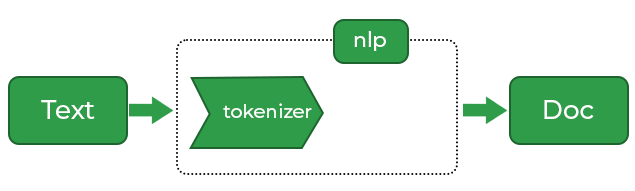
In spaCy, every NLP application consists of several steps of processing the text. when we call “nlp ” on our text, spaCy apply some processing steps.
The first step is tokenization to produce a Doc object.
The Doc object is then processed further with a tagger, a parser and an entity recognizer. This way of processing the text is called a language processing pipeline. Each pipeline component returns the processed Doc and then passes it to the next component.

import spacy
nlp = spacy.load('en_core_web_md')
doc = nlp('I went there')The Language class applies all for the preceding pipeline steps to your input sentence behind the scenes. After applying nlp to the sentence, the Doc object contains tokens that are tagged, lemmatized and marked as entities if the token is an entity.

Tokenization
The first step in a text processing pipeline is tokenization. Tokenization is always the first operation because all the other operations require tokens.
Tokenization segments texts into words, punctuations marks etc called tokens. The input to the tokenizer is a Unicode text, and the output is a Doc object. To construct a Doc object, you need a Vocab instance, a sequence of word strings.
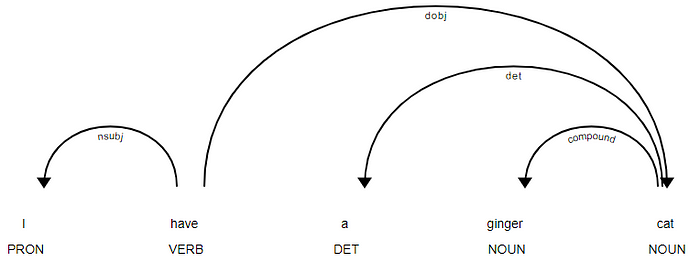
During processing, spaCy first tokenizes the text, i.e. segments it into words, punctuations as so on. This is done by rules specific to each language. Tokens can be words, numbers, punctuations, currency symbols and any other meaningful symbols that are building blocks of a sentence. The following are examples of tokens:
- Australia
- MEL
- city
- 23
- 4th
- !
- …
- ?
- ‘s
Input to the spaCy tokenizer is a Unicode text and the result is a Doc object. The following code shows the tokenization process:
Customizing Tokenizer
Most domains such as medicine, insurance or finance have at least some idiosyncrasies that require custom tokenization rules. These could be very certain expressions, or abbreviations only used in this specific field. See below on how to add special case in such circumstances:
Debugging the tokenizer
The spaCy library has a tool for debugging. We can call it by using nlp.tokenizer.explain(text). It returns a list of tuples showing which tokenizer rule or pattern was matched for each token. The tokens produced are identical to nlp.tokenizer() except for whitespace tokens:
Sentence segmentation
A Doc object’s sentences are available via the doc.sents property. The sentences can be extracted as follows:
Github
You can download the Jupyter notebook I have used in this chapter from my repository here:
https://github.com/jabirjamal/jabirjamal.com/tree/main/NLP/NLP-02
References
- Chapter 2: Mastering spaCy by Duygu Altinok
- https://spacy.io/usage/processing-pipelines